
티스토리 뷰
반응형
인공 신경망
패션 MNIST
- MNIST: 사이킷런에서 기본적으로 제공되는 데이터셋으로, 0~9개의 클래스와 28*28 크기의 흑백 데이터 6만개
- 패션 MNIST의 경우에는 10개의 클래스가 존재한다.
# keras 모듈 사용 - load_data()
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
실제로 출력해보면 이미지의 크기가 28 * 28 이다.
print(train_input.shape, train_target.shape)# 결과
(60000, 28, 28) (60000,)
print(test_input.shape, test_target.shape)# 결과
(10000, 28, 28) (10000,)
입력과 타깃 샘플
- 이전에 언급했듯, 데이터의 값은 0 ~ 255 사이에 있으며 값이 높을 수록 색이 밝아진다.
- gray_r 이라는 속성으로 색을 반전시켜 출력할 수 있다.
import matplotlib.pyplot as plt
fig, axs = plt.subplots(1, 10, figsize=(10,10))
for i in range(10):
axs[i].imshow(train_input[i], cmap='gray_r')
axs[i].axis('off')
plt.show()
10개의 데이터만 뽑아 클래스를 확인해보도록 하자.
print([train_target[i] for i in range(10)])# 결과
[9, 0, 0, 3, 0, 2, 7, 2, 5, 5]
이번엔 전체 데이터에 대해서 각 클래스의 데이터 개수를 확인해보자.
import numpy as np
print(np.unique(train_target, return_counts=True))# 결과
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000]))
로지스틱 회귀로 패션 아이템 분류하기
먼저 학습에 적용시키기 위해 데이터를 4차원에서 1차원으로 변환한다.
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
print(train_scaled.shape)# 결과
(60000, 784)
경사하강법을 손실 함수로 사용해 로지스틱 회귀를 적용해보자. 82%의 정확도를 가진 모델을 만들 수 있다.
from sklearn.model_selection import cross_validate
from sklearn.linear_model import SGDClassifier
# 'log' = 경사하강법 사용
sc = SGDClassifier(loss='log', max_iter=5, random_state=42)
# 82%의 정확도!
scores = cross_validate(sc, train_scaled, train_target, n_jobs=-1)
print(np.mean(scores['test_score']))# 결과
0.8195666666666668

로지스틱 회귀 모델의 학습 과정
- 전체 784개의 픽셀에 대해 각각의 가중치를 더해 총 10개의 Z 값을 얻는다.
- 한 마디로, 모든 픽셀은 각각의 클래스에 대해 모두 다른 가중치를 가진다.
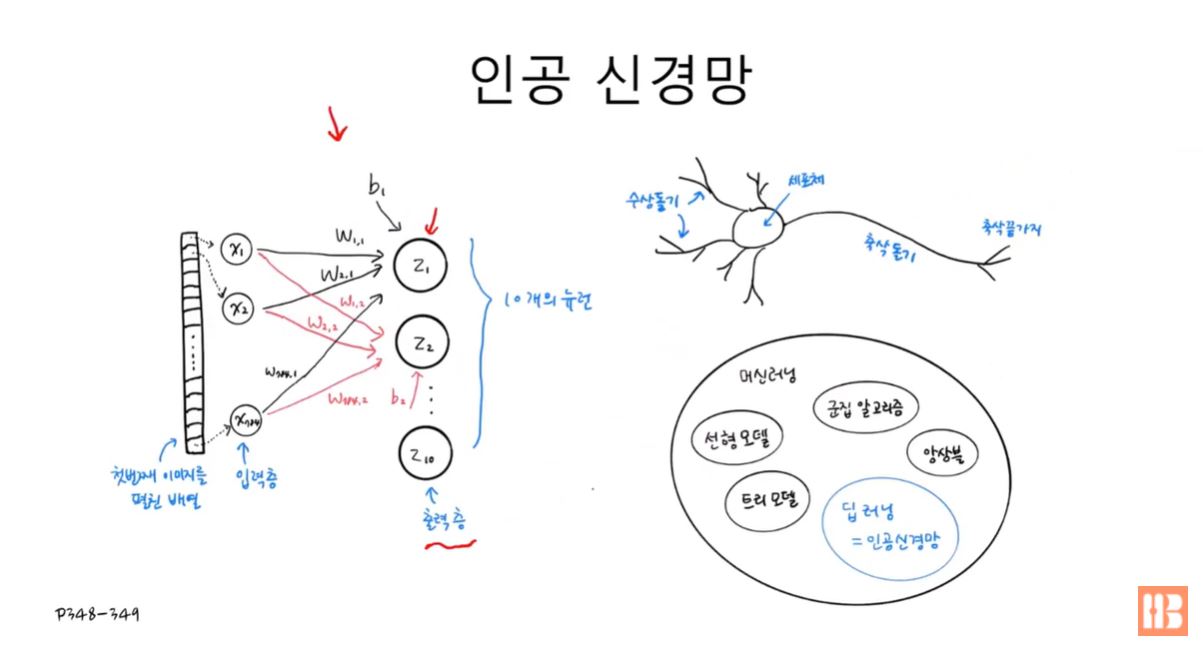
- 위의 로지스틱 회귀 모델은 인공 신경망과도 동일하게 볼 수 있다.
- 보통의 인공 신경망은 단, 입력층과 출력층 사이에 많은 은닉층이 존재한다.
- 위의 사진은 간단한 예시를 위해 은닉층이 없는 모델을 보여주고 있다.
인공신경망!
텐서플로와 케라스
인공신경망을 사용하기 위해서 우리는 텐서플로의 케라스 모듈을 사용하도록 한다.
import tensorflow as tf
from tensorflow import keras
인공신경망으로 모델 만들기
딥러닝은 다른 알고리즘과 다르게 데이터 검증이 안정되어 있으므로, 검증 없이 테스트 데이터셋만을 사용한다.
from sklearn.model_selection import train_test_split
# 딥러닝은 데이터 검증이 안정되어 있음
# 20%만 테스트 데이터셋으로 사용
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
모델을 이루는 층은 Dense 메소드로 만들 수 있다. 먼저 10개의 클래스로 이루어진 출력층을 구현해보자.
# 10개의 출력층, 활성 함수 = 소프트맥스, input_shape = 샘플의 크기
dense = keras.layers.Dense(10, activation='softmax', input_shape=(784,))
# Sequential 메소드로 모델 생성
model = keras.Sequential(dense)- 밀집층 ( = 완전연결층 ) : 모든 입력층이 모든 출력층과 연결되어 있는 경우를 말한다.
인공신경망으로 패션 아이템 분류하기
- compile() : 손실함수(loss)와 추가적인 평가 지표(metrics)를 설정할 수 있음
- sparse : 0과 1의 정수값이 아닌 0~9사이의 클래스 값을 출력할 수 있음
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
print(train_target[:10])# 결과
[8 9 4 9 6 3 6 8 2 1]
epoch를 설정하면, 하나의 에포크를 완수할 때마다 loss는 점점 감소하고, 정확도는 점점 증가한다.
# epoch 설정 -> loss는 점점 감소, 정확도는 점점 증가
model.fit(train_scaled, train_target, epochs=5)Epoch 1/5
492/492 [==============================] - 3s 3ms/step - loss: 0.7581 - accuracy: 0.7399
Epoch 2/5
492/492 [==============================] - 1s 2ms/step - loss: 0.5439 - accuracy: 0.8138
Epoch 3/5
492/492 [==============================] - 1s 2ms/step - loss: 0.4987 - accuracy: 0.8304
Epoch 4/5
492/492 [==============================] - 1s 2ms/step - loss: 0.4772 - accuracy: 0.8367
Epoch 5/5
492/492 [==============================] - 1s 2ms/step - loss: 0.4619 - accuracy: 0.8444
최종적으로 83%의 검증도를 가진 모델을 구할 수 있다.
# 83%의 검증도
model.evaluate(val_scaled, val_target)123/123 [==============================] - 0s 2ms/step - loss: 0.4885 - accuracy: 0.8311
반응형
'ML' 카테고리의 다른 글
| 혼자 공부하는 머신러닝 + 딥러닝 7장 심층 신경망 리뷰 (0) | 2022.06.12 |
|---|---|
| 혼자 공부하는 머신러닝 + 딥러닝 6장 주성분 분석 리뷰 (0) | 2022.06.10 |
| 혼자 공부하는 머신러닝 + 딥러닝 6장 K-평균 리뷰 (0) | 2022.06.10 |
| 혼자 공부하는 머신러닝 + 딥러닝 6장 군집 알고리즘 리뷰 (0) | 2022.06.10 |
| 혼자 공부하는 머신러닝 + 딥러닝 5장 리뷰 (0) | 2022.05.04 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- atq
- cat
- 리눅스cron
- 코테
- 백준
- 백준27219
- Baekjoon27211
- Baekjoon27219
- api문서
- 버추억박스에러
- GithubAPI
- 쇼미더코드
- 리눅스
- linuxtouch
- 버추억박스오류
- cron시스템
- awk프로그램
- OnActivityForResult
- linuxawk
- linuxgedit
- whatis
- SELECT #SELECTFROM #WHERE #ORDERBY #GROUPBY #HAVING #EXISTS #NOTEXISTS #UNION #MINUS #INTERSECTION #SQL #SQLPLUS
- 사용자ID
- virtualbox
- 백준27211
- baekjoon
- linux파일
- E_FAIL
- GitHubAPIforJava
- Linux
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
글 보관함