
티스토리 뷰
반응형
심층 신경망
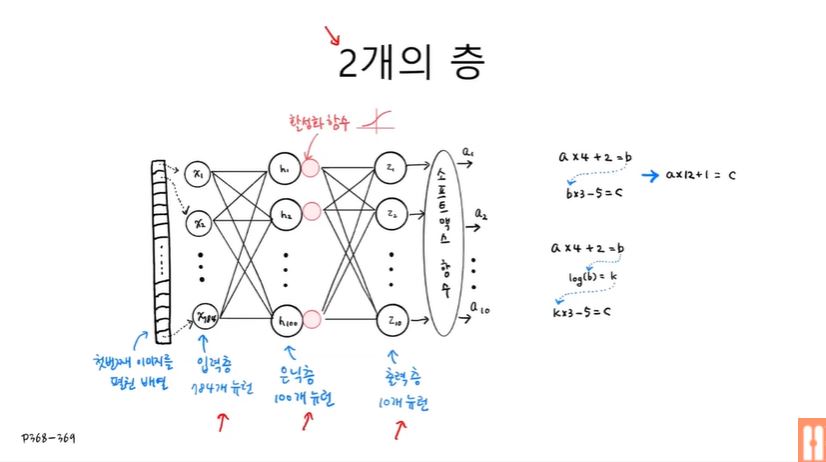
- 입력층(784개): 입력 데이터의 개수와 동일함
- 은닉층(100개): 정해진 개수는 없지만, 최소한 출력층의 개수보다 커야 손실이 발생하지 않음
- 출력층(10개): 클래스의 개수와 동일함
먼저 이전 챕터와 동일하게 패션 MNIST 데이터셋을 준비한다.
- 텐서플로우 객체 생성
import tensorflow as tf
tf.keras.utils.set_random_seed(42)
tf.config.experimental.enable_op_determinism()
- 훈련 데이터셋과 테스트 데이터셋 준비
from tensorflow import keras
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
- 데이터셋의 스케일 조정
from sklearn.model_selection import train_test_split
train_scaled = train_input / 255.0
train_scaled = train_scaled.reshape(-1, 28*28)
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
2개의 층
모델의 은닉층과 출력층을 미리 준비한다. 파라미터에는 뉴런의 개수, 활성화 함수 그리고 필요에 따라 입력 개수가 차례대로 들어간다.
# 은닉층(dense1)과 출력층(dense2) 준비하기
dense1 = keras.layers.Dense(100, activation='sigmoid', input_shape=(784,))
dense2 = keras.layers.Dense(10, activation='softmax')심층 신경망 만들기
만들어두었던 은닉층과 출력층 객체를 넣어 머신러닝 모델을 생성한다.
model = keras.Sequential([dense1, dense2])
summary() 메소드는 모델의 레이어에 대한 설명을 출력하는 메소드이다.
model.summary()# [결과]
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 100) 78500
dense_1 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________- dense의 Param = 784(입력층에서 들어오는 입력 개수) * 100 + 100(절편 개수) = 78500
- dense_1의 Param = 100(은닉층에서 들어오는 입력 개수) * 10 + 10(절편 개수) = 1010
위처럼 dense 클래스를 따로 만들지 않고 모델을 생성할 때 객체를 바로 넣어줄 수도 있다.
model = keras.Sequential([
keras.layers.Dense(100, activation='sigmoid', input_shape=(784,), name='hidden'),
keras.layers.Dense(10, activation='softmax', name='output')
], name='패션 MNIST 모델')
이미 생성한 모델에 층을 추가하고 싶을 때에는 다음과 같이 추가한다.
# 층을 추가하고 싶을 때 가장 많이 사용하는 방법
model = keras.Sequential()
model.add(keras.layers.Dense(100, activation='sigmoid', input_shape=(784,)))
model.add(keras.layers.Dense(10, activation='softmax'))
이제 모델을 학습시켜보자!
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)# 결과
Epoch 1/5
1500/1500 [==============================] - 5s 3ms/step - loss: 0.5628 - accuracy: 0.8073
Epoch 2/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.4075 - accuracy: 0.8522
Epoch 3/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.3741 - accuracy: 0.8652
Epoch 4/5
1500/1500 [==============================] - 4s 3ms/step - loss: 0.3509 - accuracy: 0.8732
Epoch 5/5
1500/1500 [==============================] - 5s 3ms/step - loss: 0.3335 - accuracy: 0.8784
렐루 활성화 함수
- relu(N) : 입력값이 0보다 작으면 0을 출력하고, 0보다 크다면 N을 출력한다. ( = max(0, 2))
- activation 파라미터에 'relu'를 넣어 렐루 함수를 사용할 수 있다.
model = keras.Sequential()
# Flatten: 28*28 이미지 크기를 784 크기의 1차원으로 펼치는 역할
model.add(keras.layers.Flatten(input_shape=(28, 28)))
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dense(10, activation='softmax'))
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)Epoch 1/5
1500/1500 [==============================] - 7s 4ms/step - loss: 0.5336 - accuracy: 0.8090
Epoch 2/5
1500/1500 [==============================] - 5s 4ms/step - loss: 0.3934 - accuracy: 0.8579
Epoch 3/5
1500/1500 [==============================] - 6s 4ms/step - loss: 0.3554 - accuracy: 0.8717
Epoch 4/5
1500/1500 [==============================] - 6s 4ms/step - loss: 0.3342 - accuracy: 0.8801
Epoch 5/5
1500/1500 [==============================] - 5s 3ms/step - loss: 0.3177 - accuracy: 0.8866
model.evaluate(val_scaled, val_target)375/375 [==============================] - 1s 2ms/step - loss: 0.3757 - accuracy: 0.8731
옵티마이저
옵티마이저 함수는 오차 범위를 줄이기 위해 값을 보정하는 역할을 수행한다. optimizer 파라미터를 통해 함수를 지정할 수 있으며 대표적으로 시그모이드와 아담 함수가 가장 많이 쓰인다.
# sgd: 확률적 경사
model.compile(optimizer='sgd', loss='sparse_categorical_crossentropy', metrics='accuracy')
직접 함수 객체를 만들어 넣어줘도 된다.
sgd = keras.optimizers.SGD()
model.compile(optimizer=sgd, loss='sparse_categorical_crossentropy', metrics='accuracy')
객체를 생성할 때에는 파라미터를 이용해 학습률, 모멘텀, nesterov 등을 설정할 수 있다.
# 학습률 설정
sgd = keras.optimizers.SGD(learning_rate=0.1)# 모멘텀이나 nesterov를 사용하고 싶은 경우에 설정
sgd = keras.optimizers.SGD(momentum=0.9, nesterov=True)
아담 함수도 같은 방법으로 사용된다.
# Adam 옵티마이저 사용법
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
model.fit(train_scaled, train_target, epochs=5)model.evaluate(val_scaled, val_target)375/375 [==============================] - 1s 2ms/step - loss: 0.3526 - accuracy: 0.8716
반응형
'ML' 카테고리의 다른 글
| 혼자 공부하는 머신러닝 + 딥러닝 7장 인공 신경망 리뷰 (0) | 2022.06.10 |
|---|---|
| 혼자 공부하는 머신러닝 + 딥러닝 6장 주성분 분석 리뷰 (0) | 2022.06.10 |
| 혼자 공부하는 머신러닝 + 딥러닝 6장 K-평균 리뷰 (0) | 2022.06.10 |
| 혼자 공부하는 머신러닝 + 딥러닝 6장 군집 알고리즘 리뷰 (0) | 2022.06.10 |
| 혼자 공부하는 머신러닝 + 딥러닝 5장 리뷰 (0) | 2022.05.04 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- Baekjoon27211
- 버추억박스오류
- 코테
- linux파일
- cron시스템
- cat
- atq
- 버추억박스에러
- awk프로그램
- virtualbox
- 백준27211
- 쇼미더코드
- 백준27219
- 리눅스
- GithubAPI
- 리눅스cron
- linuxgedit
- Linux
- whatis
- OnActivityForResult
- linuxtouch
- baekjoon
- linuxawk
- 백준
- SELECT #SELECTFROM #WHERE #ORDERBY #GROUPBY #HAVING #EXISTS #NOTEXISTS #UNION #MINUS #INTERSECTION #SQL #SQLPLUS
- GitHubAPIforJava
- E_FAIL
- api문서
- 사용자ID
- Baekjoon27219
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
글 보관함